


Imagina una plataforma de música en línea llamada Alurafy, que te permite reproducir canciones, listas de reproducción y suscribirte a dos tipos de planes. Los usuarios acceden a las páginas (URIs) y tenemos los datos en bruto en una tabla con: • columna que representa la ID de usuario (si está conectado) • columna con el URI accedido • columna con el estado de respuesta, si fue un éxito (200) o un error interno (500):
datos = pd.read_csv("todos_accesos.csv")
datos.head()

Básicamente, cada dataframe tiene un conjunto de datos que son strings y, a menudo, no nos damos cuenta, cuáles son los nombres de las columnas: URI, Usuario conectado y Status de respuesta:
datos.columns
Resultando en:
Index(['URI', 'Usuario conectado', 'Estado de respuesta'], dtype='object')
Son nombres razonablemente descriptivos, pero horribles de acceder. Por ejemplo, no pudimos acceder a:
datos.Usuario conectado
Pero solamente:
datos['Usuario conectado']
Por supuesto, no es una gran pérdida. Pero tenemos mayúsculas y minúsculas mezcladas, no hay un estándar claro. ¿Qué tal estandarizar todas estas strings?
Para esto tomamos los nombres de las columnas y mediante el atributo str logramos ponerlos todos en letra minúsculas:
datos.columns.str.lower()
Resultando en columnas en minúsculas:
Index(['uri', 'usuario conectado', 'estado de respuesta'], dtype='object')
Pero los espacios en blanco siguen ahí. Podemos tomar esta serie de datos, usar de nuevo el str y reemplazar los espacios con guiones bajos:
datos.columns.str.lower().str.replace(' ', '_')
Por fin, las columnas con los nombres que quería:
Index(['uri', 'usuario_conectado', 'estado_de_respuesta'], dtype='object')
Si asignamos los valores de estas columnas a sí mismas:
datos.columns = datos.columns.str.lower().str.replace(' ', '_')
datos.head()
Y esta línea de estandarización de nombres de columnas se puede usar en casi todos los proyectos inmediatamente después de importar un csv.
Ahora echemos un vistazo a las páginas accesadas a través de tus URI:
datos.uri.unique()
array(['/', '/canciones', '/contacto', '/playlist/drumnbass',
'/playlist/funk', '/compra/plan_basico', '/playlist/techno',
'/promocion_primero_de_abril/compra/plan_basico',
'/compra/plan_avanzado', '/playlist/pop', '/playlist/rock',
'/playlist/jazz', '/playlist/clasica', '/playlist/kpop'],
dtype=object)
Ahora me gustaría crear una nueva columna indicando si al acceder a esta página el usuario quería comprar algo. Es decir, ¿la URI comienza con /compra/? Si es,True, si no False. Para esto tenemos la función startswith:
datos['comprando'] = datos.uri.str.startswith("/compra")
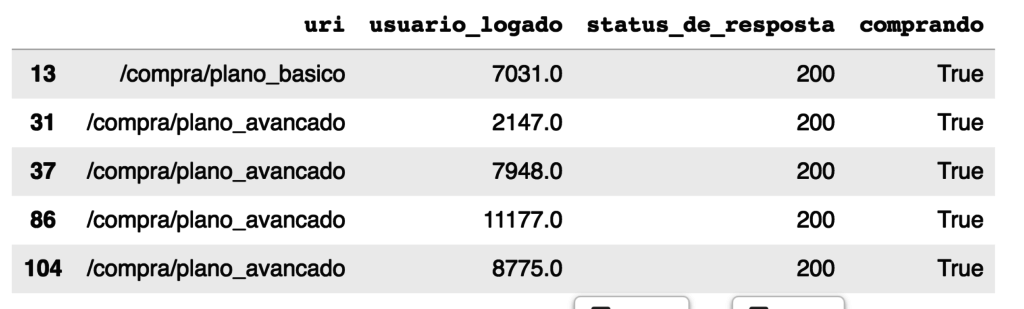
Así que estamos buscando en una columna de string/texto las líneas que comienzan con un determinado valor. Ahora imprimimos con una query los primeros 5 elementos que están con True:
datos.query("comprando==True").head()
Resultando en:
Para agrupar y contar el número de páginas de compra versus el número de otras páginas, tomemos la columna comprando y sumamos sus valores:
datos.comprando.value_counts()
Y notamos que tenemos alrededor del 9,5% de visitas a las páginas de compras:
False 164295
True 15705
Name: comprando, dtype: int64
Por fin, cometimos un error. De hecho, también hay páginas de compra como del día 1 de abril en /promocion_primero_de_abril/compra/plan_basico. Por lo tanto, no solo queremos las URI que comienzan con /compra/ pero que tienen en el medio el tramo /compra. Además de la función startswith, str nos permite realizar varias otras funciones, como contains:
datos['comprando'] = datos.uri.str.contains("/compra/")
datos.query("comprando==True").head()

Ahora sí, creamos la nueva columna de acuerdo con cualquier página que tenga el tramo /compra/ en su URI.
En resumen, siempre que necesites trabajar con una columna de tipo string, para extraer valores de ella, hacer transformaciones de string a string, echa un vistazo a la documentación de la str a ver si ya tiene lo que quieres hacer. Hay decenas de funciones.

Guilherme cofundó Caelum, Alura y GUJ. Con más de 15 años de experiencia enseñando programación y habilidades digitales, coordina los equipos de producción de cursos en Alura. Es un tecnólogo con sesgo matemático y medallista de oro en competiciones nacionales de computación, representando a Brasil en los mundiales. Participante activo en la comunidad open source y de educación en tecnología, autor de 7 libros en el área.
